
Paginación SEO-Friendly: Guía Práctica con «Cargar Más» y «Scroll Infinito»
Dividir el contenido en páginas puede ser un arma de doble filo: mejora la experiencia del usuario, pero puede bloquear a Googlebot si no se implementa correctamente. Aquí aprenderás cómo hacerlo bien.
 Gean Materan
Gean Materan
La paginación mal implementada puede hacer que Googlebot pierda decenas o cientos de páginas de tu sitio sin que te des cuenta. En esta guía vas a aprender cómo estructurar la paginación estándar, el botón «Cargar Más» y el scroll infinito para que tanto tus usuarios como Googlebot encuentren todo el contenido.

Para mostrar un subconjunto de una lista más grande, puedes elegir entre diferentes patrones de UX. Paginación, Cargar más o Desplazamiento infinito
¿Qué es la Paginación?
La paginación es el proceso de dividir un conjunto grande de contenido —como productos, artículos o resultados de búsqueda— en varias páginas web separadas para reducir el tiempo de carga y mejorar la experiencia de usuario.
Tradicionalmente se hace con enlaces de navegación numéricos (1, 2, 3, Siguiente) al pie de la página. Sin embargo, hoy muchos sitios optan por patrones más dinámicos:
Paginación Estándar
Links numerados al final de la página. La más simple y la más segura para SEO.
- URLs únicas por página
- Rastreable por defecto
- Fácil de implementar
Cargar Más (Load More)
Un botón que añade más elementos a la página actual vía AJAX sin recargar.
- Mejor UX que paginación
- Requiere enlaces rastreables
- Necesita SSR para SEO
Scroll Infinito
Los elementos se cargan automáticamente al llegar al final de la página.
- Máximo engagement UX
- Mayor riesgo SEO
- Requiere History API
⚠️ El problema clave: Googlebot no emula el comportamiento de hacer clic en un botón ni de desplazarse. Sin la implementación correcta, el rastreador solo verá la primera página y no indexará el resto del contenido.
Renderizado del Lado del Cliente vs. del Lado del Servidor
Entender cómo se carga tu página es el primer paso para una paginación SEO-friendly:
| Tipo de Renderizado | Cómo funciona | ¿Googlebot lo ve? | Recomendación SEO |
|---|---|---|---|
| Del Lado del Servidor (SSR) | El servidor devuelve el contenido completo al realizar una solicitud GET. | ✓ Sí. Todo visible en el código fuente. | Preferido. Googlebot ve todo el contenido al instante. |
| Del Lado del Cliente (CSR) | El contenido se renderiza con JavaScript después de cargar el HTML inicial. | ✗ Puede que no. El contenido vía JS puede ser invisible. | Úsalo junto con SSR para paginación. Nunca solo. |
(SSR)Server Side Rendering
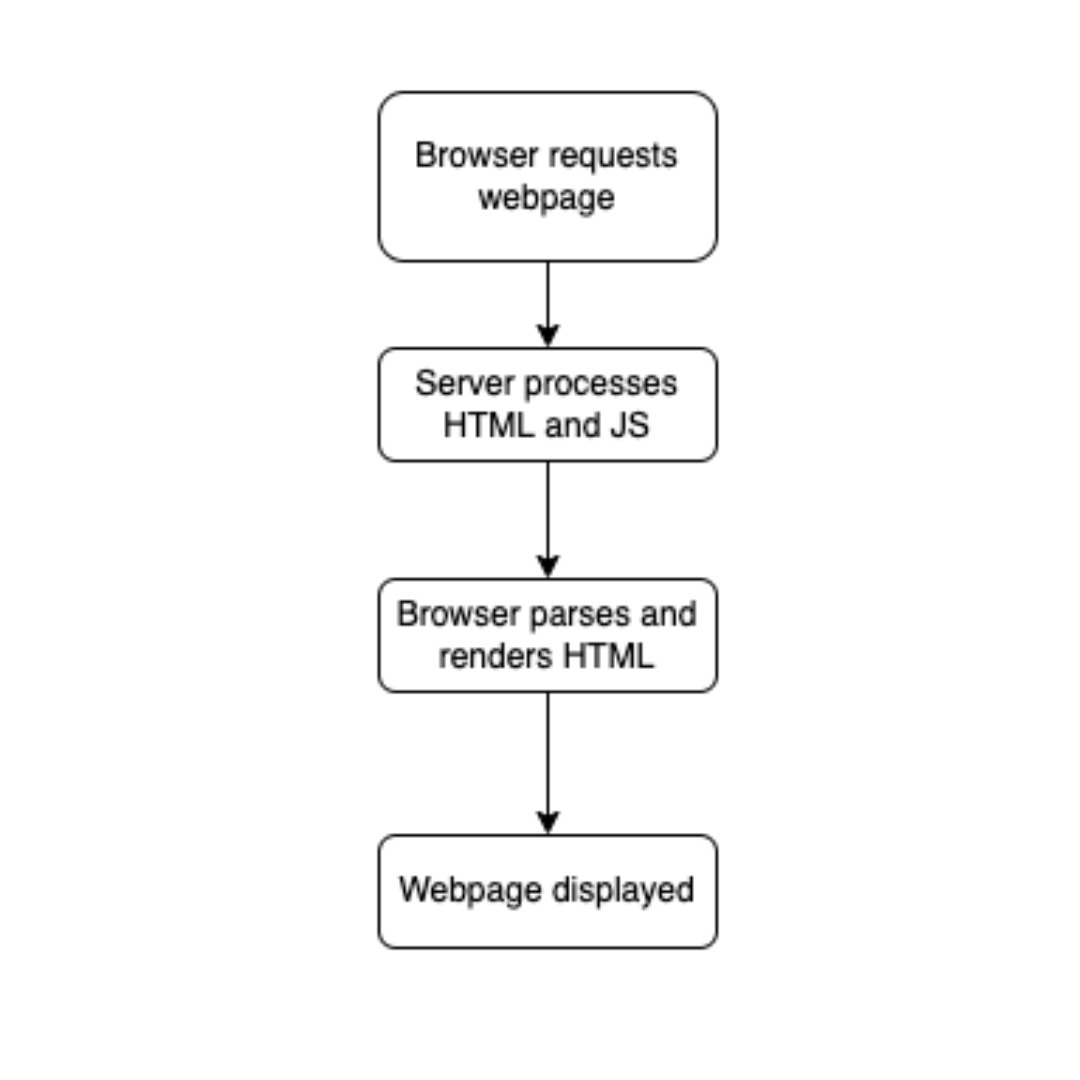
Ejemplo de como funciona el renderizado del lado del lado servidor (SSR).
Client Side Rendering (CSR)
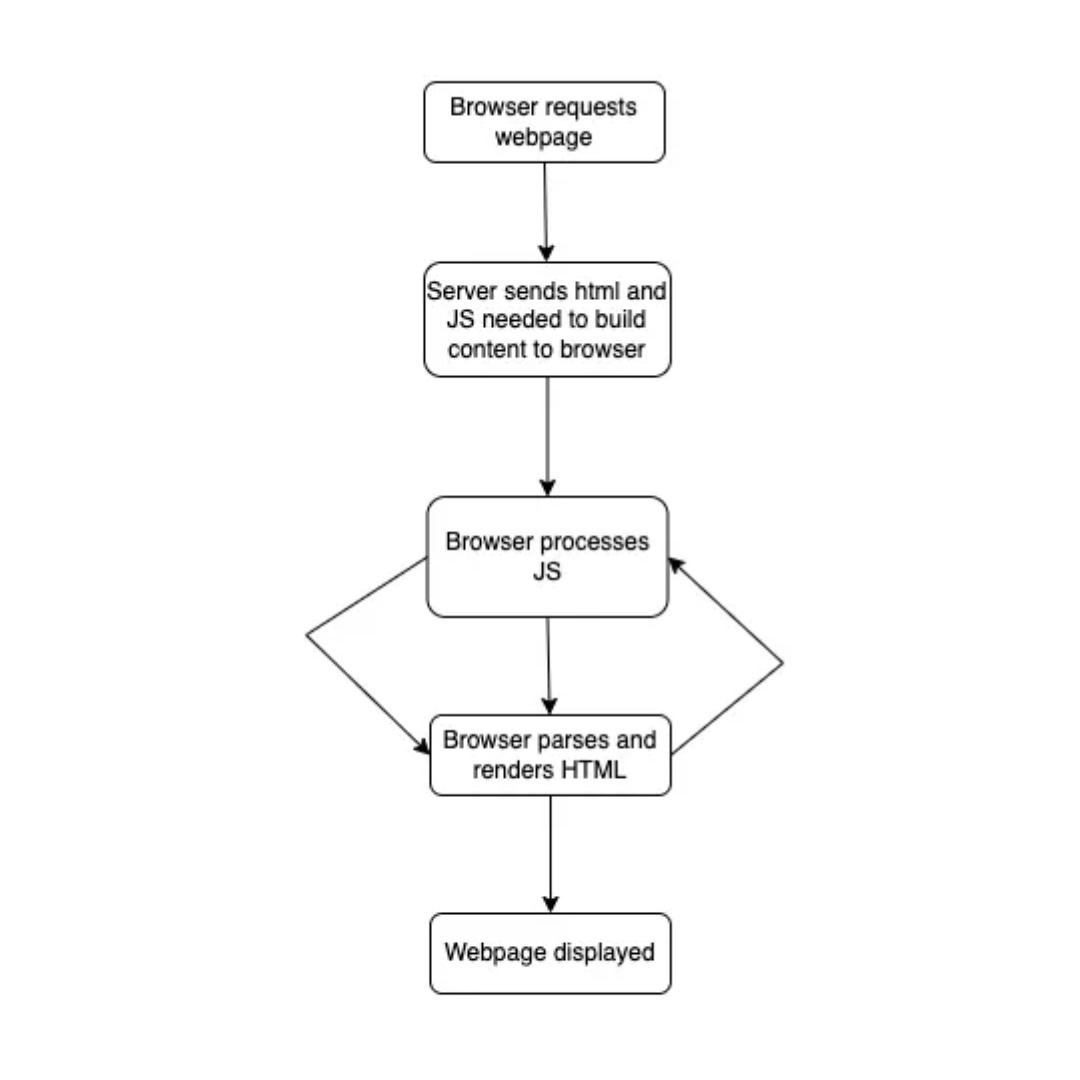
Ejemplo de como funciona el renderizado del lado del cliente (CSR).
Mejores Prácticas de Paginación
Lo que DEBES hacer
- Usar etiquetas canónicas auto-referenciales en cada página paginada
- Usar etiquetas
<a>con URLs rastreables para vincular páginas - Asegurar que cada elemento sea único en esa página (sin duplicados entre páginas)
- Colocar el contenido descriptivo único solo en la primera página
- Usar parámetros de URL claros:
?page=1,?page=2 - Usar History API para actualizar la URL correcta al navegar con JS
- Usar SSR para que los elementos estén en el código fuente al cargar la URL directa
Lo que NO DEBES hacer
- Usar
rel=canonicalapuntando a la primera página desde todas las demás - Usar controladores de eventos de JS para la navegación (sin etiqueta
<a>) - Usar
rel=next/rel=prev(Google ya no los utiliza) - Usar
noindexen páginas paginadas - Acumular todos los ítems anteriores en cada página (
?page=3no debe tener los de páginas 1 y 2) - Duplicar el texto descriptivo del listado en todas las páginas paginadas
Errores Comunes a Evitar
| Problema Común | Descripción | Consecuencia SEO |
|---|---|---|
| URL única para todo | SPAs que cargan más contenido vía AJAX sin cambiar la URL. | Googlebot solo ve una URL y no indexa el contenido adicional. |
| Contenido acumulativo | ?page=10 contiene todos los ítems de las páginas 1 a 10. |
Crea páginas duplicadas; Google puede posicionar paginadas en lugar de la principal. |
| Descripción duplicada | El mismo texto descriptivo del listado en todas las páginas paginadas. | Páginas muy similares que confunden a Google y afectan el ranking. |
Ejemplos de Implementación SEO-Friendly
La clave para «Cargar Más» y «Scroll Infinito» amigables con el SEO es simple: para Googlebot, cada paso de la paginación debe ser una URL única y rastreable renderizada en el servidor, incluso si el usuario lo experimenta como una interacción dinámica.
1. Paginación Estándar
La más sencilla. Vinculas secuencialmente de la página 1 a la última. Googlebot sigue los enlaces <a> de forma nativa:
<!-- Navegación paginada estándar -->
<nav aria-label="Paginación">
<a href="/blog?page=1" rel="canonical">1</a>
<a href="/blog?page=2">2</a>
<a href="/blog?page=3">3</a>
<a href="/blog?page=2" rel="next">Siguiente →</a>
</nav>
<!-- Canónica auto-referencial (va en el <head>) -->
<link rel="canonical" href="/blog?page=2" />- ✓ Elementos únicos por página
- ✓ Renderizado en el servidor
- ✓ Enlaces rastreables con etiqueta
<a> - ✓ URL única por página
- ✓ Canónica auto-referencial
2. Cargar Más (Load More)
El usuario hace clic en un botón para cargar más ítems vía AJAX, pero Googlebot puede rastrear los enlaces directos a las páginas paginadas. El truco está en que el botón sea siempre una etiqueta <a>:
<!-- El botón DEBE ser una etiqueta <a> con href rastreable -->
<a href="/productos?page=2" id="load-more-btn">
Cargar Más
</a>document.getElementById('load-more-btn').addEventListener('click', function(e) {
e.preventDefault(); // Detiene la navegación para el usuario
const nextPage = this.getAttribute('href');
// Carga solo los ítems de la siguiente página
fetch('/api/productos?page=2')
.then(res => res.json())
.then(items => {
appendItemsToGrid(items); // Añade ítems al DOM
history.pushState(null, '', nextPage); // Actualiza la URL
updateLoadMoreButton(nextPage); // Actualiza el botón al ?page=3
});
});✓ Clave SSR: Si alguien accede directamente a /productos?page=2, el servidor debe devolver solo los ítems de la página 2, no todos los de página 1 + 2.
3. Scroll Infinito (Infinite Scroll)
Los ítems se cargan automáticamente al llegar al final. Para Googlebot, cada sección del scroll debe corresponder a una URL rastreable:
// Observa cuando el centinela al final de la página entra en viewport
const sentinel = document.getElementById('scroll-sentinel');
const observer = new IntersectionObserver((entries) => {
if (entries[0].isIntersecting && hasMorePages) {
const nextUrl = `/productos?page=${currentPage + 1}`;
fetch(`/api/productos?page=${currentPage + 1}`)
.then(res => res.json())
.then(items => {
appendItemsToGrid(items);
history.pushState(null, '', nextUrl); // Actualiza la URL al scrollear
currentPage++;
});
}
});
observer.observe(sentinel);⚠️ Importante: Debes incluir también una paginación estándar oculta visualmente (pero no con display:none) para que Googlebot descubra todas las URLs paginadas mediante el rastreo de enlaces.
Detalles Técnicos de la Paginación SEO-Friendly
La estrategia se basa en el principio de Graceful Degradation: aunque la página use JavaScript para interacciones dinámicas, debe funcionar correctamente incluso si Googlebot tiene JavaScript deshabilitado.
1. El Fundamento: Renderizado del Lado del Servidor (SSR)
- URLs Únicas y Directas: Cada página paginada debe tener una URL propia (ej:
/productos?page=2). Al acceder directamente, el servidor responde con el contenido completo de esa página. - Contenido No Acumulativo:
/productos?page=3muestra solo los ítems de la página 3, nunca los de páginas 1 y 2 acumulados.
2. Navegación Rastreable (Crawler-Friendly Links)
- Siempre etiquetas
<a>: El botón «Cargar Más» y los disparadores del scroll deben ser etiquetas<a>con atributohrefapuntando a la siguiente URL paginada. - Nunca uses solo
onclickoaddEventListenersin unhrefreal.
3. Interceptación con JavaScript (para el Usuario)
- Interceptar el evento: Usa JS para interceptar el clic en el enlace.
- Prevenir navegación: Llama a
e.preventDefault()para evitar que el usuario recargue la página. - Solicitud AJAX: Envía una solicitud asíncrona para obtener los ítems de la siguiente página.
- Insertar contenido: Añade los nuevos ítems al DOM dinámicamente.
4. Actualización de URL (History API)
// Después de insertar el contenido de la Pág 2 en el DOM:
const nextPageUrl = '/productos?page=2';
history.pushState(null, '', nextPageUrl);
// La URL del navegador ahora muestra /productos?page=2
// sin haber recargado la página.5. Canonicalización
- Canónicas auto-referenciales: Cada página paginada apunta a sí misma.
- No canonizar a la página 1: Si
/productos?page=3tienecanonicalapuntando a/productos, Googlebot puede dejar de rastrear las demás páginas.
Tabla resumen: Usuario vs. Googlebot
| Acción | Usuario | Googlebot | Requisito SEO |
|---|---|---|---|
| Página de Aterrizaje | Ve la Pág 1 completa. | Pide y recibe el HTML de la Pág 1 (SSR). | SSR con contenido único |
| Rastreo / Interacción | Clic en botón <a> o scroll. JS intercepta. |
Sigue el enlace <a> a la Pág 2. |
Enlaces rastreables <a> |
| Carga de Contenido | JS realiza Fetch/AJAX y añade ítems al DOM. | Pide y recibe el HTML de la Pág 2 (SSR). | SSR con contenido único |
| Actualización | El navegador actualiza la URL con history.pushState(). |
Pasa a rastrear los enlaces de la Pág 2. | URL única por página |
✓ Principio clave: El enlace rastreable <a> siempre debe apuntar a la versión SSR de la siguiente página. Esto garantiza que tanto el usuario como Googlebot siempre tengan acceso al contenido completo.
La paginación SEO-friendly no es una cuestión de elegir entre la mejor experiencia de usuario y el SEO. Con la implementación correcta de SSR, enlaces rastreables, History API y canonicalización, puedes tener ambos. El resultado: más contenido indexado, más páginas posicionadas, más tráfico orgánico.
Preguntas Frecuentes
¿El scroll infinito es malo para el SEO?
No necesariamente. El scroll infinito es malo para el SEO solo si no se implementa con SSR y URLs rastreables. Con la estrategia de Graceful Degradation, Googlebot puede indexar todo el contenido mientras los usuarios disfrutan de la experiencia dinámica.
¿Sigue siendo útil rel=next y rel=prev?
No. Google declaró en 2019 que ya no usa estas etiquetas. Lo que realmente importa es que cada página paginada tenga una URL única, contenido propio (no acumulativo), y sea rastreable con etiquetas <a> con href.
¿Debo poner noindex en las páginas paginadas para evitar contenido duplicado?
No. Las páginas paginadas deben ser indexables para que Googlebot pueda llegar a los elementos que contienen. En lugar de noindex, usa canónicas auto-referenciales y asegúrate de que cada página tenga contenido único.
¿Cómo sé si Googlebot está viendo todas mis páginas paginadas?
Revisa en Google Search Console cuántas URLs de tu serie paginada están indexadas. Si solo aparece la primera, el problema es que Googlebot no puede seguir los enlaces a las siguientes. También puedes revisar el Log de Rastreo en GSC para ver qué URLs visita el bot.
¿Necesitas ayuda con la implementación técnica?
Una paginación mal configurada puede costarte cientos de páginas sin indexar. Hablemos sobre cómo auditar y optimizar la arquitectura de tu sitio.
Contactar ahora →